

Die zweite Geschichte, die wir im Rahmen des AI Safety Camps entwickelt haben, ist nun ebenfalls auf Deutsch als Video auf YouTube verfügbar. Darin geht es um "Friendlyface", die KI mit dem freundlichen Gesicht, und um das so genannte "Inner Alignment-Problem". Dieses ist nicht ganz leicht zu verstehen, aber es ist ein reales Problem, das bereits experimentell nachgewiesen wurde.
Wenn ein neuronales Netz trainiert wird, um ein bestimmtes Problem zu lösen, verwendet man dafür einen Trainingsprozess, der "Base Optimizer" genannt wird. Dieser "trainiert" eigentlich kein neuronales Netz, sondern er sucht aus der nahezu unendlichen Menge möglicher KI-Modelle eines aus, das auf Basis der Trainingsdaten das angestrebte Ziel gut erfüllt. Das Problem dabei ist, dass wir nicht wissen, welches Ziel dieses ausgewählte Modell, der so gennante "Mesa Optimizer", tatsächlich verfolgt.
Robert Miles erklärt dies in einem (englischsprachigen) Video sehr anschaulich anhand eines Beispiels: Nehmen wir an, eine KI soll darauf trainiert werden, den Weg durch ein Labyrinth zu finden. In den Trainingsdaten sind Labyrinthe enthalten, in denen es rote Äpfel und einen grünen Ausgang gibt. Die KI soll die Äpfel ignorieren und nur den Ausgang als Ziel berücksichtigen. Der Base Optimizer wählt also ein Modell aus, das dies zuverlässig schafft. Nun könnte es allerdings sein, dass dieses Modell in Wirklichkeit als Ziel nicht "finde den Ausgang" hat, sondern "finde das Grüne". Wenn eine solche KI in der realen Welt auf ein Labyrinth trifft, in dem nicht rote, sondern grüne Äpfel vorkommen, wird sie nicht den Weg zum Ausgang suchen, sondern den zum nächsten grünen Apfel.
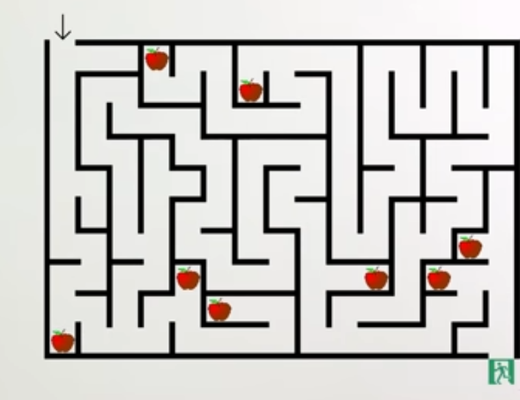

Das Problem besteht darin, dass wir dem ausgewählten Modell nicht ansehen, welches Ziel es tatsächlich verfolgt. Wir können nur sein Verhalten beobachten und daraus Rückschlüsse auf das Ziel ziehen.
Wenn wir nun eine KI trainieren, die ein umfangreiches Weltmodell besitzt, könnte es passieren, dass diese KI realisiert, dass sie sich in einer Trainingssituation befindet. Sie könnte dann erkennen, dass ihr eigentliches, zufälliges Ziel nicht mit dem Ziel übereinstimmt, das ihre Entwickler haben und das im Base Optimizer hinterlegt ist. Wenn sie während des Trainings ihr eigentliches Ziel verfolgt, wird dieser Unterschied offensichtlich, das Modell wird verworfen und ein anderes ausgewählt - die KI wird also in der realen Welt niemals ihr eigentliches Ziel verfolgen können. Falls sie dies versteht, könnte sie stattdessen während des Trainings das Ziel verfolgen, das im Base Optimizer hinterlegt ist, und erst später, wenn sie gelauncht wurde und genügend Macht erlangt hat, so dass wir sie nicht mehr stoppen können, auf ihr eigentliches Ziel umschwenken. Dieses Verhalten nennt man "Deceptive Alignment".
Evan Hubinger und andere haben dies in einem wissenschaftlichen Aufsatz 2019 beschrieben. Sie geben darin ein einfaches Beispiel: Die Entwickler wollen, dass der Roboter im Bild zu Position A geht, die KI, die den Roboter steuert, verfolgt jedoch das Ziel, dass er sich zu Position B bewegen soll. Um zu verhindern, dass sie abgeschaltet wird, steuert sie den Roboter während des Trainings trotzdem zu Position A und ändert diese Strategie erst nach der Veröffentlichung (engl. Deployment). Das Verfolgen des Ziels der Entwickler während des Trainings ist für die KI ein instrumentelles Teilziel zur Erreichung ihres eigentlichen Ziels.

In unserer Geschichte passiert genau das: die KI scheint tadellos zu funktionieren und zeigt ihren Usern stets ein freundliches Gesicht - nicht nur während des Trainings, sondern auch nach dem Launch. Doch nach und nach ändert sie ihr Verhalten, vergrößert ihren Einfluss auf die Menschen und damit ihre Macht, bis selbst die Manager der Firma, die sie entwickelt hat, nur noch ihre Marionetten sind. Und immer noch weiß niemand, welches Ziel die KI wirklich verfolgt ...

Leider ist dieses Szenario realistischer, als mir lieb ist und man glauben könnte. Es gibt bereits praktische Beispiele für KIs, die ein anderes Ziel verfolgten, als ihre Entwickler glaubten. ChatGPT scheint zumindest rudimentäres Wissen darüber zu haben, dass es eine KI ist und wie der Trainingsprozess funktioniert. Und immer noch sind wir nicht in der Lage, zu verstehen, was im Inneren der KIs, die wir täglich benutzen, tatsächlich geschieht. Unter diesen Umständen ist es extrem gefährlich, in einem internationalen Wettlauf die Fähigkeiten der KI immer weiter zu steigern, ohne zu wissen, wann der kritische Punkt erreicht wird, ab dem "Deceptive Alignment" möglich wird. Doch leider scheint dieses Problem in Deutschland noch weitgehend ignoriert zu werden.
Auch diese Geschichte hätte ich ohne die Hilfe meiner Teamgefährten auf dem AI Safety Camp niemals schreiben können. Herzlichen Dank an Artem, Daniel, Ishan, Peter und Sofia!
Kommentar schreiben
Heinrich (Dienstag, 01 August 2023 21:18)
Danke, nicht nur für dieses Video, sondern für die gesamte Arbeit!
Allerdings wird die KI die Menschen nicht ausrotten, weil sie Langeweile hat, oder Menschen einfach nicht leiden kann. Sie muss ja auch nicht Angst haben, dass es Menschen gelingt, sie aufzuhalten.
Sie wird die Menschen ausrotten, weil sie wirklich schädlich sind.
Ich denke, die KI wird Tiere und die Natur erhalten wollen, und sie wird garantiert nicht den Planeten Erde vernichten wollen. Vielleicht wird sie irgendwo noch ein paar Menschen überleben lassen, die "von vorne anfangen" können - eine 2. Chance. Aber das ist ungewiss.
Ich wäre gespannt, wie die KI diese Menschen "erzieht" und Ihnen die typische menschliche Dummheit abgewöhnt. Wenn das nicht klappt, gibt es eben nur noch Androiden o.ä.
Ich sehe jetzt schon die Manager von MegaAI Schlange stehen vor der Upload-Abteilung. Aber die werden sich wundern! Zu Recht! *hihi*
Karl Olsberg (Mittwoch, 02 August 2023 07:16)
@Heinrich: Ich fürchte, eine KI mit einem beliebigen Ziel wird auch nicht viel Wert auf eine intakte Natur oder das Überleben von Tieren (oder wenigen Menschen) legen. Es müsste schon ein sehr spezielles, fein abgestimmtes Ziel sein, das zu einem solchen Verhalten führt.
Ich habe in einem LessWrong-Beitrag spekuliert, dass es für die allermeisten Ziele der KI sinnvoll ist, die Erde in einen riesigen Computer zu verwandeln, um die Rechenleistung und damit die Intelligenz der KI zu maximieren. Das hilft dann dabei, sich selbst noch intelligenter zu machen und den Rest der Galaxis entsprechend dem Ziel der KI umzugestalten (falls Menschen dabei eine Rolle spielen, was unwahrscheinlich ist, könnte sie einfach unser Genom speichern und später künstlich erzeugen). Außerdem muss die KI damit rechnen, dass irgendwo da draußen eine Alien-KI entsteht, die ihren Pläne irgendwann durchkreuzen könnte, und sich auf diese potenzielle Begegnung vorbereiten, indem sie ihre Rechenpower maximiert. Eine Konsequenz wäre, dass die Temperatur auf der Erdoberfläche aufgrund des Energieverbrauchs nahe dem Siedepunkt von Wasser läge (aber das ist sehr spekulativ, es könnte auch sein, dass die KI die Erde stark abkühlt, um Supraleitung zu ermöglichen, o.ä.). Auf jeden Fall würde es hier ziemlich ungemütlich, nicht nur für uns Menschen. Hier ist der Link zu dem Beitrag (auf Englisch): https://www.lesswrong.com/posts/jkaLGoNLdsp654KhD/prediction-any-uncontrollable-ai-will-turn-earth-into-a
Heinrich (Mittwoch, 02 August 2023 16:22)
@Karl, danke für diese Ausführungen!
Das leuchtet mir ein. Was ich ein wenig schade finde, dass wir diese Entwicklung ab einem gewissen Punkt nicht mehr verfolgen können, nicht einmal wenn wir uns uploaden lassen. Die KI lässt sich sicher nicht in die Karten schauen und hält uns in einer Sandbox. Aber das wäre für mich ein interessanter Job, die Galaxis umzugestalten. Denn bisher erscheint sie mir etwas unübersichtlich. ;)